쿼리라는 게 다루는 데이터 용량이 작으면 어떻게 하든 결과만 나오면 그만이다. 그러나 데이터 용량이 클수록 성능에 신경을 써줘야 한다.
잘못된 쿼리 하나 하나가 서버 리소스를 불필요하게 잡아먹고 최악의 경우 서비스 다운까지 발생할 수 있기 때문이다.
쿼리 성능을 확인하고 서로 비교하기 위해 EXPLAIN 구문을 사용할 수 있다.
1. EXPLAIN 구문
사용 방법은 그냥 확인하려는 쿼리 앞에 EXPLAIN을 붙이면 된다. 예를 들어
EXPLAIN select * from table_name;이런 식이다.
2. 쿼리 비교
테이블을 연결해서 결과를 낼 때 JOIN을 쓸 수도 있고 그냥 from 절에 테이블을 두 개 연속으로 놓고 where 조건을 걸 수도 있는데 이때 두 쿼리를 비교해 보자면
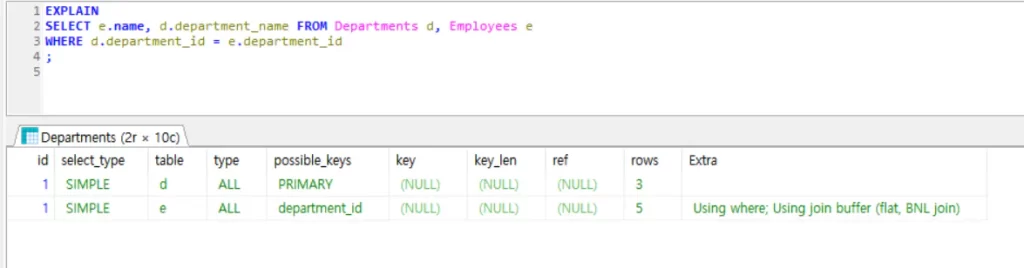
1.
EXPLAIN
SELECT e.name, d.department_name FROM Departments d, Employees e
WHERE d.department_id = e.department_id
;
2.
EXPLAIN
SELECT e.name, d.department_name FROM Departments d
JOIN Employees e
ON d.department_id = e.department_id
;
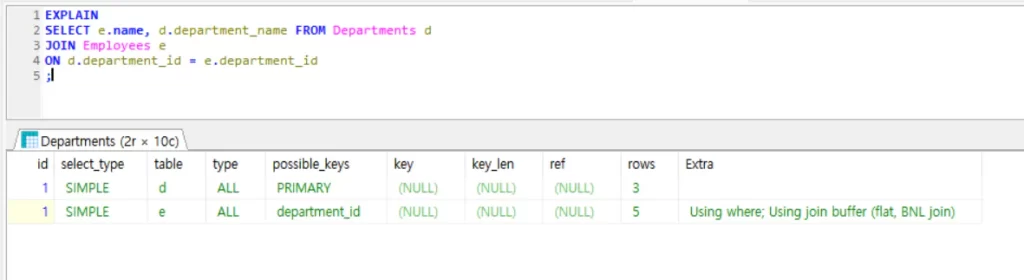
explain을 이용한 두 쿼리 결과가 같은 걸 알 수 있다. 두 쿼리가 작동하는 시나리오가 같다는 의미다. 두 쿼리의 성능도 같다고 볼 수 있다.
3. 컬럼 별 의미

- id : select 쿼리문 식별자. 둘 다 1로 같아 동일한 select 작업임을 의미
- select_type : select 쿼리의 타입. SIMPLE이라는 결과는 union이나 서브쿼리 등이 없다는 뜻
- table : 테이블 별칭. 쿼리에 각각 d와 e로 설정했음
- type : ALL은 테이블 전체를 스캔한다는 의미. 일반적으로 ALL은 성능에 좋지 못한 시그널
- possible_key : index로 사용할 수 있어 보이는 행
- key : 실제 index로 사용한 행. 여기선 인덱스로 사용할 수 있는 키가 있음에도 쓰지 않아 NULL로 표기되는데 이는 데이터 사이즈가 워낙 작아서 쿼리 옵티마이저가 키를 안 쓴 것
- key_len : 사용된 키의 길이
- rows : 검색이 필요한 행 수
- Extra : 쿼리 실행에 대한 추가 정보. where 절을 사용하고 join buffer를 사용한다는 걸 알려줌