SQL에서 중복을 제거하는 방법은 그 목적에 따라 다양합니다. distinct를 쓸 수도 있고 group by를 쓸 수도 있고 ROW_NUMBER() 같은 함수를 이용할 수도 있어요.
이 글에선 특정 컬럼만을 기준으로 중복을 제거하는 게 목적입니다. 그래서 group by를 사용합니다.
SELECT * FROM customers ORDER BY city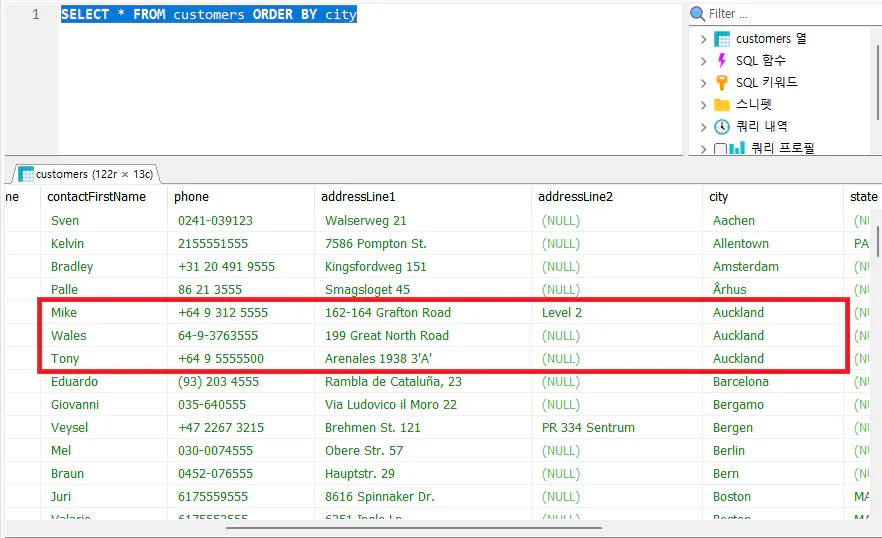
city 컬럼에 Auckland 라는 데이터가 중복되어 표시되고 있습니다.
저는 전체 컬럼을 조회하고 싶고 city 컬럼에는 중복이 없는 게 목적입니다. group by로 city를 묶으면 됩니다.
SELECT * FROM customers GROUP BY city ORDER BY city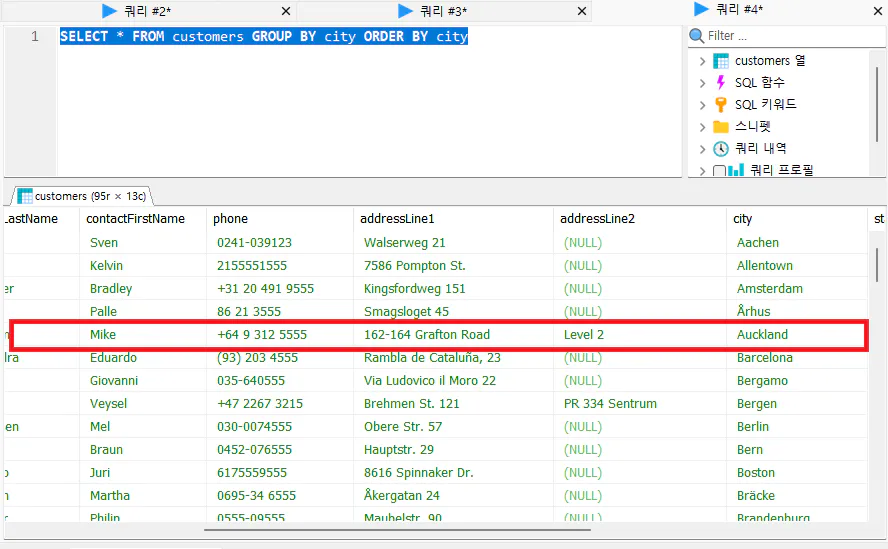
city 컬럼의 중복이 제거됐습니다. order by 구문은 눈으로 확인하기 위함이니 빼셔도 상관없습니다.
이때 주의할 사항은 city가 Auckland인 다른 행들이 사라진다는 건데요. 원래는 이렇게 무책임하게(?) 조회하면 어떤 기준으로 다른 행을 남길지 물어봐야 하는 게 맞습니다.
하지만 알아서 mysql의 기준으로 다른 행을 제거하는 모습입니다. 남겨야 하는 행의 기준이 있다면 어떤 행을 남겨야할지를 추가로 조건을 명시해서 쓰시면 됩니다.
근데 사실 ‘중복제거’라는 개념에서 가장 먼저 떠오르는 건 distinct 입니다. ‘왜 group by를 써야할까?’ 싶을 수도 있습니다. 조회해보면 답이 나옵니다.
SELECT DISTINCT * FROM customers ORDER BY city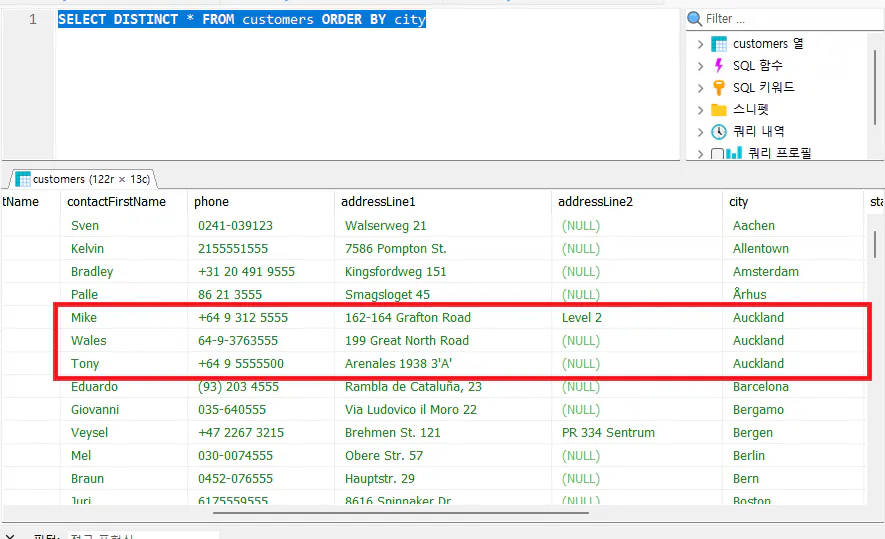
city 컬럼의 중복이 제거되지 않았습니다. 왜냐하면 distinct는 특정 단일 컬럼을 기준으로 중복을 제거하는 게 아니라 컬럼의 ‘조합’에 대한 중복을 제거하기 때문입니다.
조회된 행을 보면 city 값은 같지만 다른 컬럼들의 값은 다릅니다. 그러니 distinct는 이걸 중복으로 인식하지 않고 유니크한 행으로 인식합니다.