관계형 데이터베이스에서 인덱스는 쿼리 성능을 향상시키기 위해 사용한다. 인덱스는 하나의 컬럼에 생성되는 단일 인덱스와 두 개 이상의 컬럼에 생성되는 복합 인덱스로 구분할 수 있다.
가령 이건 단일 인덱스 생성이다.
CREATE INDEX idx_department_id ON employees (department_id);그리고 이건 복합 인덱스 생성이다.
CREATE INDEX idx_department_role ON employees (department_id, role_id);이때 한 가지 의문이 생기는데
CREATE INDEX idx_department_id ON employees (department_id);
CREATE INDEX idx_department_role_id ON employees (role_id);이렇게 단일 인덱스를 나눠서 생성하는 거랑
CREATE INDEX idx_department_role ON employees (department_id, role_id);이렇게 복합 인덱스를 한 번에 생성하는 게 차이가 있나? 라는 것이다.
1. 복합 인덱스
당연히 차이가 있으니까 복합 인덱스라는 게 있는 것이다.
복합 인덱스는 where 절에 and 로 여러 개의 컬럼의 조건을 만족시키는 쿼리를 수행할 때 유리하다.
예를 들어 아래의 테이블에
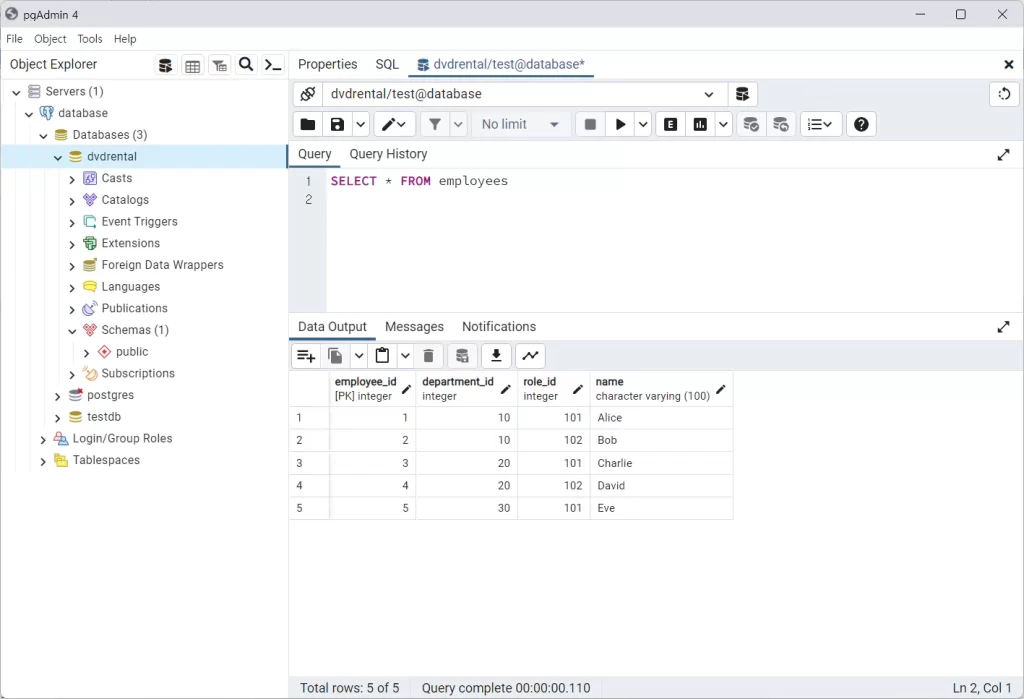
복합 인덱스를 생성했다.
CREATE INDEX idx_department_role ON employees (department_id, role_id);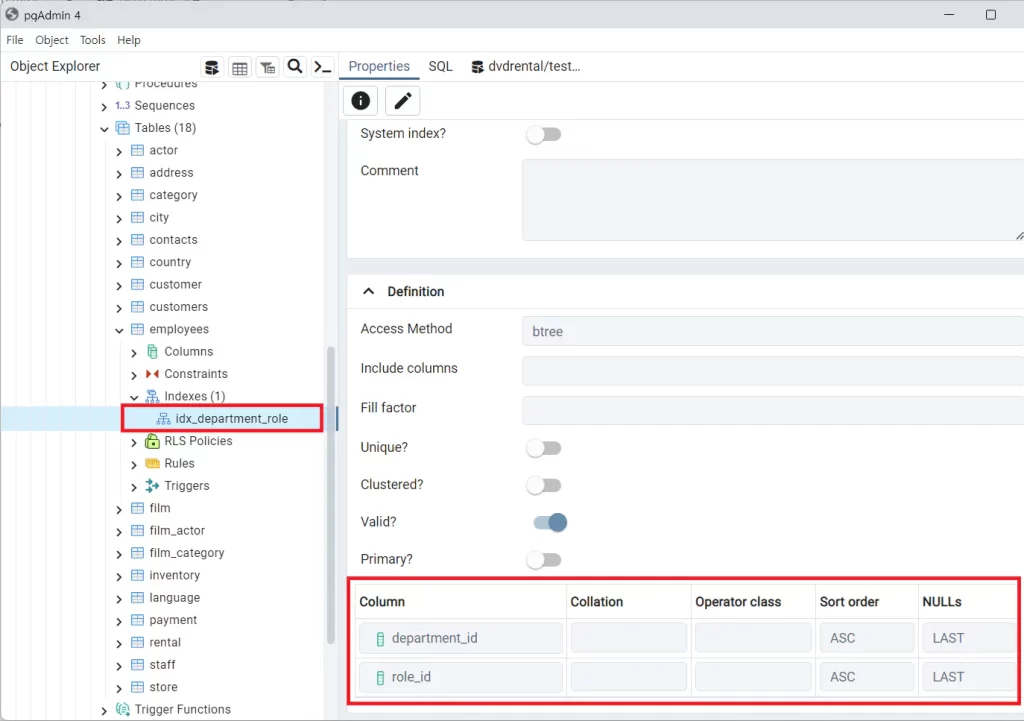
이런 테이블 구조에서 아래와 같은 필터링 조건을 만족시킬 때 유리하다.
SELECT * FROM employees WHERE department_id = 20 AND role_id = 101;explain으로 확인해보면
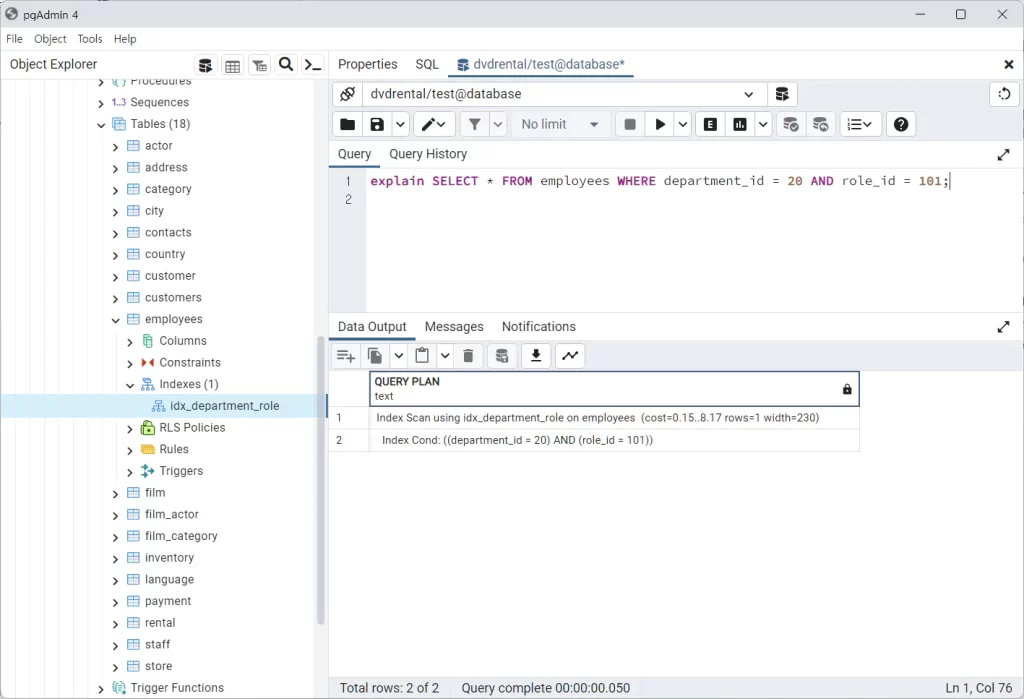
department_id과 role_id를 동시 조건으로 사용하는 인덱스 스캔을 하는 걸 볼 수 있다.
2. 단일 인덱스
같은 테이블에 복합 인덱스 대신 단일 인덱스 여러 개를 만들어 비교해본다.
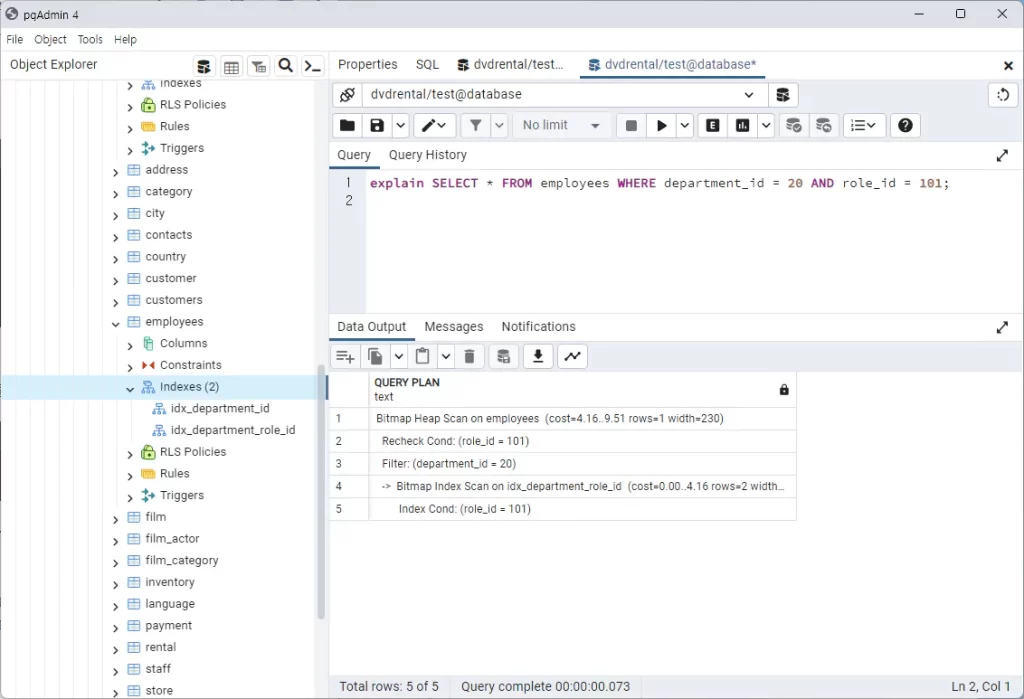
이번엔 비트맵 힙 스캔 방식을 사용하는 걸 볼 수 있는데 먼저 role_id에 대해서만 비트맵 인덱스 스캔을 수행하고 그 결과에 대해 department_id 조건을 필터링하는 방식을 사용한다.
결과적으로 복합 인덱스의 최종 cost는 8.17 단일 인덱스의 최종 cost는 9.51로 복합 인덱스의 성능이 더 좋았다. 테이블 데이터가 많아질수록 해당 쿼리의 성능은 복합 인덱스 쪽이 더욱 좋을 것이다.
3. 복합 인덱스로 단일 조건 조회
한 가지 더 알아야 하는 게 있다. 복합 인덱스를 생성할 때는 맨 앞에 오는 컬럼이 중요하다.
예를 들어
CREATE INDEX idx_department_role ON employees (department_id, role_id);이렇게 인덱스를 생성했으면 department_id에 대해서는 추가적인 이점이 있다. department_id 컬럼에 단일 인덱스를 생성하는 것과 비슷한 효과를 얻을 수 있다.
SELECT * FROM employees WHERE department_id = 20이런 쿼리를 할 때도 위의 복합 인덱스가 성능을 향상시킨다. 이건 복합 인덱스가 첫번째 컬럼을 데이터의 맨 앞에 저장하기 때문이다.
반면 두번째 컬럼인 role_id의 경우 단일 조건으로 필터링 할 경우 인덱스가 기여하지 못한다.
내용을 정리하면 테이블 조회는 여러 시나리오로 수행될 수 있는데 두 개 이상의 조건이 함께 필터링되는 패턴이 많이 쓰이는 경우엔 함께 쓰이는 조건을 조합해서 복합 인덱스 사용을 고려한다. 그리고 복합 인덱스 생성할 땐 더 많이 쓰이는 조건 컬럼을 첫번째 순서에 두는 게 좋다.